The Math Breakthrough
Renormalized Diffusion on Graphs
Old Cleora computed all walks exactly. New Cleora computes them — and then refuses to let them collapse the representation.
The Core Idea in One Sentence
New Cleora turns plain graph diffusion into a renormalized dynamical system. After each sparse propagation step, it re-centers and whitens the entire node-embedding cloud, counteracting the spectral collapse that usually makes deep message passing unusable.
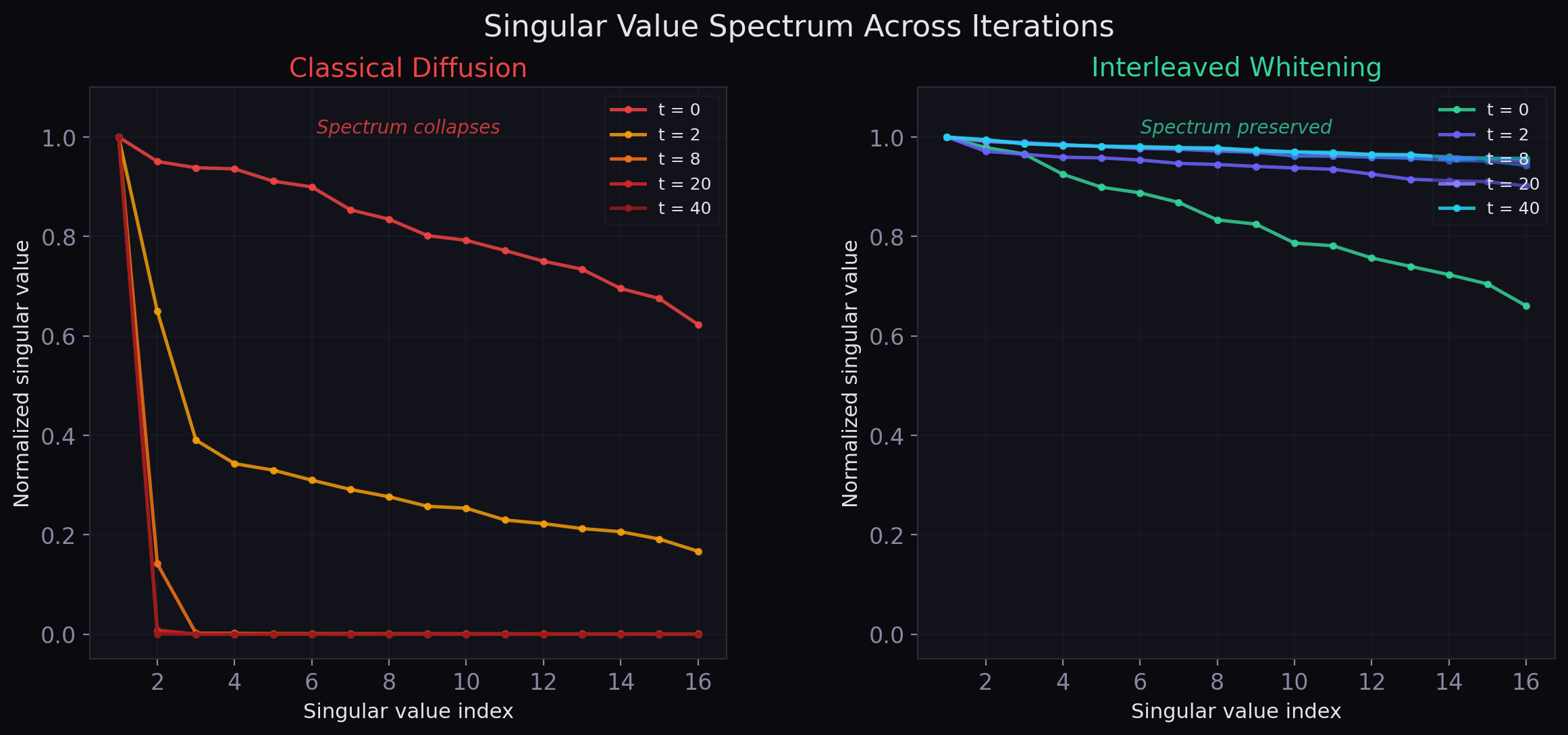
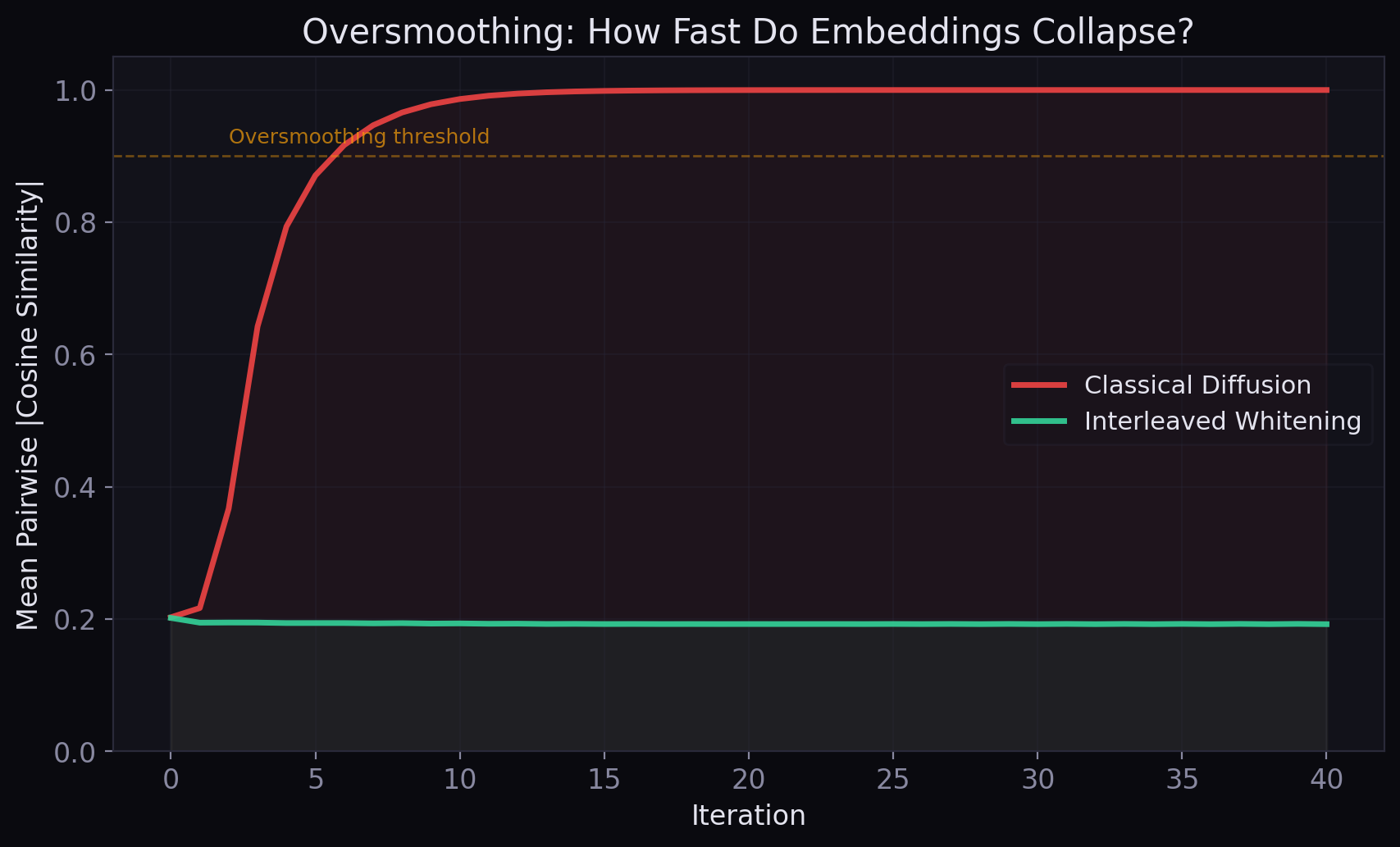
Classical message passing mixes information. That is its strength, and also its failure mode. Repeated averaging pushes node representations toward a small number of dominant graph modes, causing oversmoothing, loss of rank, and eventual collapse toward trivial directions.
New Cleora introduces a mathematically decisive correction: interleaved whitening. Instead of merely propagating and row-normalizing, it periodically re-centers the node cloud and equalizes variance across all feature directions. The effect is striking: much deeper propagation becomes not only possible but genuinely informative, without backpropagation, trainable parameters, or GPU hardware.
Propagation explores the graph. Whitening preserves the subspace.
Not more parameters. Better geometry.
The Original Cleora Operator
Let \(G = (V, E)\) be a graph with \(n = |V|\) nodes. Let \(d\) be the embedding dimension, \(X_t \in \mathbb{R}^{n \times d}\) the node embedding matrix at iteration \(t\), and \(M\) a graph propagation operator — typically either:
Left Markov
Row-stochastic. Each row sums to 1. Equivalent to a random walk transition matrix.
Symmetric Markov
Preserves spectral properties. Eigenvectors form the graph's spectral embedding.
The original Cleora iteration is:
where \(\mathcal{N}_{\text{row}}\) performs row-wise \(\ell_2\) normalization.
This is already powerful. A single sparse matrix multiplication aggregates all weighted one-step neighbor information simultaneously; repeating it accumulates multi-hop structure without random-walk sampling or gradient-based training. It is deterministic, parameter-free, and scales with sparse linear algebra rather than stochastic training.
But mathematically, the original iteration inherits the generic failure mode of repeated diffusion.
Why Classical Diffusion Collapses
If \(M\) is a connected row-stochastic operator, then under mild conditions:
where \(\pi\) is the stationary distribution. Therefore:
This is a rank-one object: every node tends toward the same direction, modulated only by a global average. In graph ML language, this is the familiar oversmoothing phenomenon. The more one propagates, the more one loses node-level discrimination.
Row-wise \(\ell_2\) normalization helps stabilize magnitudes and cosine geometry, but it does not fully solve the spectral problem. It rescales each row independently; it does not restore lost rank, reopen collapsed singular directions, or decorrelate features globally.
The classical tradeoff: more iterations bring more global structural context — but also more collapse toward the dominant graph modes. This is not a software bug. It is a mathematical inevitability of the diffusion operator itself.
New Cleora attacks this tradeoff at the source.
The New Recurrence: Propagation + Whitening
The new operator inserts a full-covariance whitening step between propagation stages. The recurrence becomes:
where \(\rho \in [0,1)\) is an optional residual weight, \(\mathcal{N}_{\text{row}}\) keeps each node vector on the unit sphere, and \(\mathcal{W}\) is the whitening operator.
Sparse Markov Propagation
Multiply by the graph operator. Aggregate all walks of the current length in parallel.
Exact graph walk aggregationRow \(\ell_2\) Normalization
Project each node vector back onto the unit sphere \(S^{d-1}\). Preserve cosine geometry.
Local angular stabilizationFull-Covariance Whitening
Center the node cloud. Compute the \(d \times d\) covariance. Apply inverse square root. Return to isotropic position.
Global isotropy restorationThe whitening operator, precisely
For a matrix \(Y \in \mathbb{R}^{n \times d}\), define its centered version and feature covariance:
If \(\Sigma = V \Lambda V^\top\) is the eigendecomposition of the feature covariance, then PCA whitening is:
This makes the output centered and approximately isotropic:
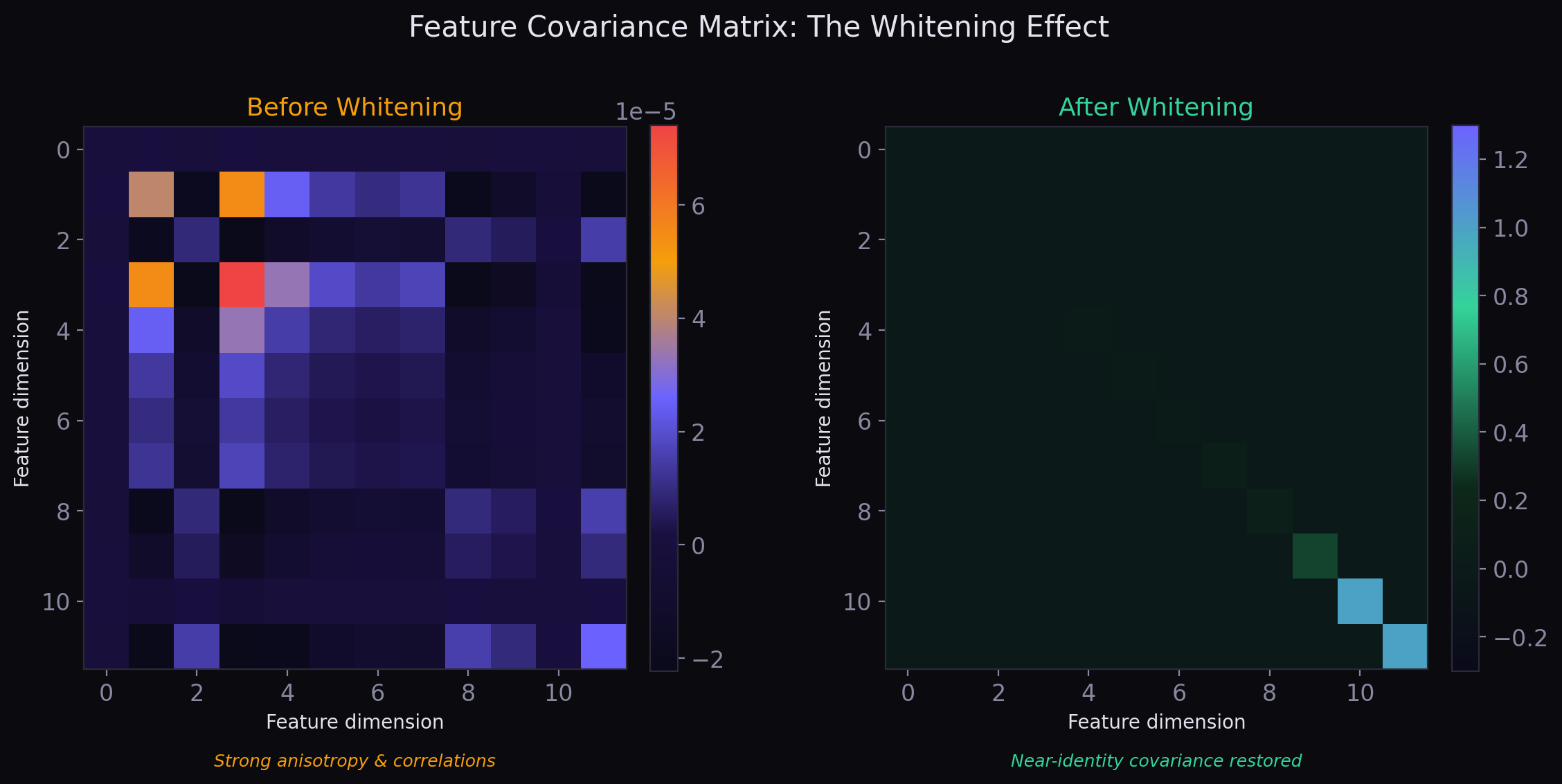
This is not cosmetic normalization. It is a global geometric intervention that couples every feature dimension to every other feature dimension.
The One-Equation Punchline
Suppose the centered matrix has singular value decomposition:
where \(U \in \mathbb{R}^{n \times d}\) has orthonormal columns, \(S\) is diagonal with singular values, and \(V\) is orthogonal. Then:
Therefore PCA whitening gives:
The whitening step discards the singular values and keeps the orthogonal subspace basis. Diffusion tries to collapse the spectrum; whitening throws that collapse away and retains the geometry of the informative subspace itself.
This identity is mathematically beautiful and conceptually decisive. A plain diffusion step says: keep multiplying by \(M\), let dominant modes win, let weak modes die. A whitened diffusion step says:
- Propagate through the graph
- Remove the common-mode drift
- Equalize the surviving directions
- Continue
So the new Cleora does not merely smooth more. It repeatedly asks: "After this diffusion step, which directions of variation across nodes still matter?" — and then rescales those directions so they remain usable in the next step.
Why This Is More Than “Just Another Normalization”
It is tempting to think of whitening as a cosmetic post-processing step. It is not. The distinction is fundamental.
Row Normalization (Local)
Treats each node independently:
Preserves angular geometry at the node level. Does not couple feature dimensions. If two columns become nearly redundant, row normalization will not restore diversity.
Whitening (Global, Second-Order)
Uses the full covariance matrix \(\Sigma\):
Every feature dimension is coupled to every other. Global anisotropy is measured and corrected. Collapsed directions are reopened. Redundant directions are decorrelated.
The original Cleora diffuses each coordinate mostly on its own. The new Cleora measures the geometry of the whole node cloud, then globally rebalances that geometry before the next diffusion step. This is the decisive mathematical innovation.
What centering removes
In repeated averaging systems, one of the dominant failure modes is drift toward a shared, nearly constant direction across all nodes. Centering explicitly removes that common-mode component before re-scaling:
New Cleora does not merely slow collapse; it actively projects away the most trivial part of the collapse.
Key insight: Whitening does not invent signal. It prevents existing signal from being buried under spectral imbalance.
Spectral View: From Power Iteration to Orthogonal Iteration
Without whitening, repeated application of \(M\) behaves like a power method:
Whenever \(M\) has a spectral gap, repeated multiplication increasingly favors dominant eigenmodes. This is the basic mathematical reason why deep diffusion oversmooths.
Interleaving whitening changes that picture profoundly. The new iteration becomes much closer to block power iteration / orthogonal iteration:
Power Iteration (Old Regime)
- Keep pushing everything into the single easiest direction
- Dominant modes win; weak modes die
- Effective rank collapses monotonically
- Depth is self-defeating
Orthogonal Iteration (New Regime)
- Track a whole informative subspace
- Diffusion identifies graph-coherent directions
- Whitening removes anisotropy, resets the singular spectrum
- Next step explores from a full-rank, isotropic state
In numerical linear algebra, this distinction is well understood: power iteration extracts the dominant mode and collapses everything else. Orthogonal iteration preserves a whole subspace. Interleaved whitening upgrades Cleora from one to the other.
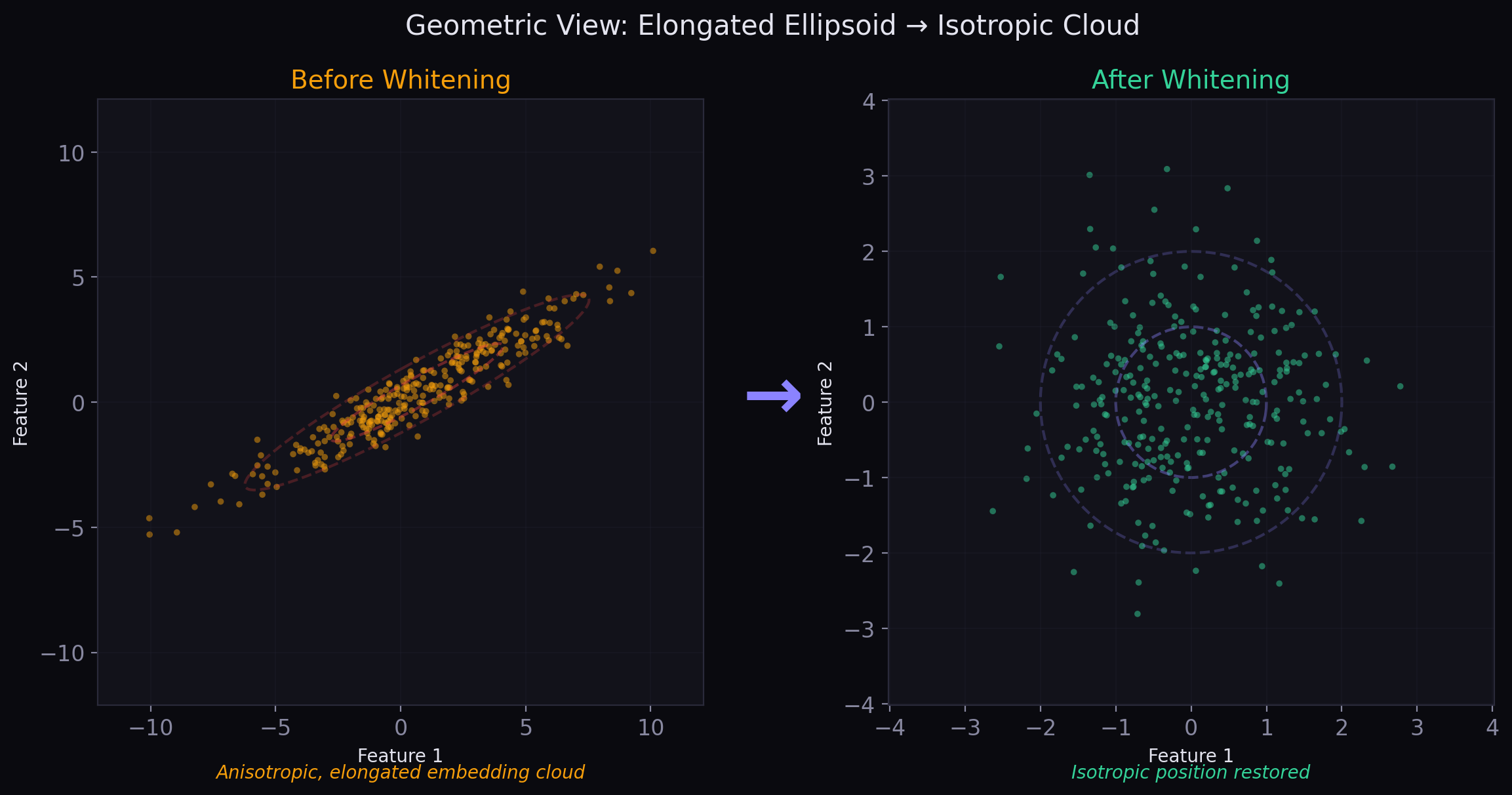
Geometric View: A Product of Spheres Plus Isotropic Position
There is a clean geometric story underlying the new recurrence. The method alternates between two entirely different kinds of geometric constraints.
Local Geometry
Row normalization constrains each node embedding to unit norm. After each propagation step, every row lives on the sphere \(S^{d-1}\). Across all nodes, the state lives on a product manifold:
This is a node-local constraint: each individual vector is retracted back to the sphere.
Global Geometry
Whitening acts on the entire cloud of node embeddings at once. By centering and applying the inverse square root of the covariance, it places the cloud into isotropic position:
This is a cloud-global constraint: the ensemble is shaped as a whole.
One full iteration of new Cleora can therefore be read as an alternating procedure between:
- A graph-local averaging operator (propagation)
- A node-local norm constraint (row normalization)
- A global feature-space isotropy constraint (whitening)
That is why the method feels qualitatively different from a standard MPNN layer stack. It is not just aggregating messages. It is alternating between propagation and geometric correction.
Physics View: Renormalized Diffusion
There is a useful physics metaphor that makes the dynamics immediately intuitive.
- Diffusion is a coarse-graining operation: it smooths away high-frequency detail, suppresses local noise, amplifies low-frequency global modes.
- Whitening is a renormalization step: it rescales the surviving degrees of freedom so they remain comparable and usable.
In ordinary diffusion, the flow drifts toward a trivial fixed point. In new Cleora, each whitening step says: not yet.
It subtracts the collapsed mean mode, rescales the remaining directions, and sends the system back into the next diffusion step with restored representational balance. This is why the method can be described as renormalized diffusion on graphs.
The innovation is not more message passing. The innovation is what happens between message-passing steps.
Why Deep Iteration Becomes Meaningful
The original Cleora already made a key observation: a few propagation steps can capture local and medium-range structure extremely well. But eventually classical diffusion saturates. Interleaved whitening changes what "more iterations" means.
Old Regime
- More iterations mostly increase smoothness
- Eventually all nodes start to look alike
- Depth becomes self-defeating
- Iteration count is a fragile hyperparameter
New Regime
- Each iteration still aggregates higher-order walk information
- Whitening repeatedly removes drift and restores isotropy
- Later steps keep revealing new higher-order structure
- Iteration count becomes a meaningful scale parameter
Whitening frequency as a new control axis
Interleaved whitening introduces a genuinely new degree of algorithmic control:
- Whiten every step: strongest anti-collapse behavior
- Whiten every \(q\) steps: allows some diffusion accumulation between reconditioning steps
- Final whitening only: improves output conditioning but does not fundamentally change the trajectory
The user can tune not just propagation depth, but the rhythm of renormalization. Combined with the optional residual weight \(\rho\), this creates a rich family of parameter-free graph embedding dynamics:
The residual term lets Cleora interpolate between pure graph diffusion and persistence of the current representation, further stabilizing very deep iteration regimes.
Why This Remains Scalable
A critical practical point: whitening happens in feature space, not graph space.
Propagation Cost
Sparse matrix multiplication. Scales with the number of edges, not nodes squared.
Whitening Cost
Works through a \(d \times d\) covariance matrix. The dense step scales with embedding dimension, not node count.
The graph itself may have millions of nodes, but the covariance is only \(d \times d\). The difficult dense linear algebra happens over the embedding dimension, not over the number of nodes. Conceptually, the algorithm is still sparse-graph-first. It adds a small dense correction in feature space to guide a very large sparse propagation in node space.
The new Cleora preserves every property of the original philosophy:
- Sparse linear algebra over huge graphs
- Fully deterministic computation
- Strong CPU efficiency
- No training loop, no negative sampling, no GPU dependency
But it adds a much richer geometry to the iteration itself.
Permutation Equivariance Is Preserved
A global operation often raises an obvious concern: does whitening break the symmetry that graph models should respect? It does not.
If the rows of \(Y\) are permuted by a permutation matrix \(P\), then \(Y \mapsto PY\). The row mean is unchanged (averaging over rows is permutation-invariant), and the covariance is also unchanged:
Therefore the whitening transform is the same, and:
So whitening is global but still permutation-equivariant. The method gains a genuinely nonlocal correction without sacrificing one of the central symmetries of graph representation learning.
What This Means for Graph ML
The standard deep-learning narrative says message passing has a depth problem: too few iterations means not enough context; too many means oversmoothing and rank collapse. New Cleora suggests a different path entirely.
The problem is not message passing itself. The problem is letting contraction accumulate without any global geometric correction. Interleaved whitening introduces precisely that correction.
What becomes newly plausible
- Deeper parameter-free propagation without immediate collapse
- Global covariance steering without attention mechanisms
- Spectral balancing without trainable filters
- Subspace-preserving diffusion instead of blunt smoothing
The broader principle: After every operator that mixes information, restore isotropy before mixing again. This principle is immediately relevant to MPNNs, deep graph diffusion, graph transformers, and even transformer language models, where the attention matrix itself is a graph-like propagation operator.
A scientifically careful statement about WL-style limits
New Cleora does not refute theorems about anonymous message passing. It changes the regime. Cleora uses deterministic identity-based initialization rather than anonymous all-equal node features. Interleaved whitening is a global full-covariance operator that couples feature dimensions. The whole pipeline remains permutation-equivariant, but it is no longer the usual "independent local aggregator per channel" picture.
So the correct claim is not that "WL theory is wrong." The correct claim is stronger in practice and cleaner in theory:
Interleaved whitening moves Cleora outside the narrow regime where the usual depth-collapse intuition dominates. This is not a denial of theory, but a construction that steps around the assumptions that made the old pessimism seem inevitable.
What is genuinely new
For a mathematical or ML audience, the novelty can be stated cleanly:
- Cleora was already an exact, deterministic sparse propagation algorithm.
- The new Cleora adds full-covariance whitening inside the recurrence, not merely as post-processing.
- That converts a collapsing diffusion into an orthogonalized, renormalized multi-step graph embedding flow.
- The method remains parameter-free, deterministic, sparse, and CPU-friendly.
Further Reading
The original Cleora paper introducing deterministic iterative neighbor averaging and normalization.
Technical deep-dive into the Rust core, Markov propagation, and implementation internals.
Relevant for the broader whitening literature and the PCA-vs-ZCA distinction.
Relevant to the broader theme of orthogonalization as geometric steering in neural networks.
The broader message-passing / rank-collapse story in transformers.
The new Cleora shows that graph representation learning does not need to choose between elegance and power. Sparse Markov propagation already gave Cleora a deterministic alternative to sampling-heavy graph ML. Interleaved whitening takes the next step: it turns propagation into a geometry-aware dynamical system that can keep discovering structure at depths where ordinary diffusion would already be fading into a trivial limit.
Exact graph propagation becomes dramatically more expressive when each step is followed by global isotropy restoration.